Join the SMCClab

Currently Recruiting! I’m currently looking for PhD students in the field of musical machine learning, particularly for projects focussed on using AI/ML in live performance!
If you’re passionate about music, interaction, and computing, and want to be a part of an innovative school at one of the world’s top universities, get in touch through ANU!
There are three ways to learn about sound, music and creative computing in my lab:
-
Take one of my classes (see below)—I teach Bachelor- and Master-level classes for computing students and other students around ANU.
-
Apply to do an Honours or Master project with me. If you apply to do a project but haven’t completed any creative computing courses at ANU, I will probably advise you to go back to step 1 and take a course first to learn the basics.
-
Apply to become a PhD or MPhil student in my lab. This is for folks who already have excellent results in a computing or creative technology degree and experience in creative computing. You’ll need to get in touch with me well before applications are due.
I will next recruit student projects in January 2024. I will next recruit PhD students in the application round due in April 2024.
Courses
I currently teach:

PhD/MPhil Research Students
I supervise PhD, Master, and Honours students at the ANU and at University of Oslo. My previous students’ published work is listed here. You can see my current students on my lab page.
My students have gone on to work at Google, Seeing Machines, Oslo Metropolitan University, and other wonderful places.
I’m only able to accept students who have excellent results in a computing or creative technology degree at the Master or Honours level and who have existing experience in computing for a creative field. Interest in music or art is not enough, experience needs to be clearly demonstrated through projects and (hopefully) publications or a thesis.
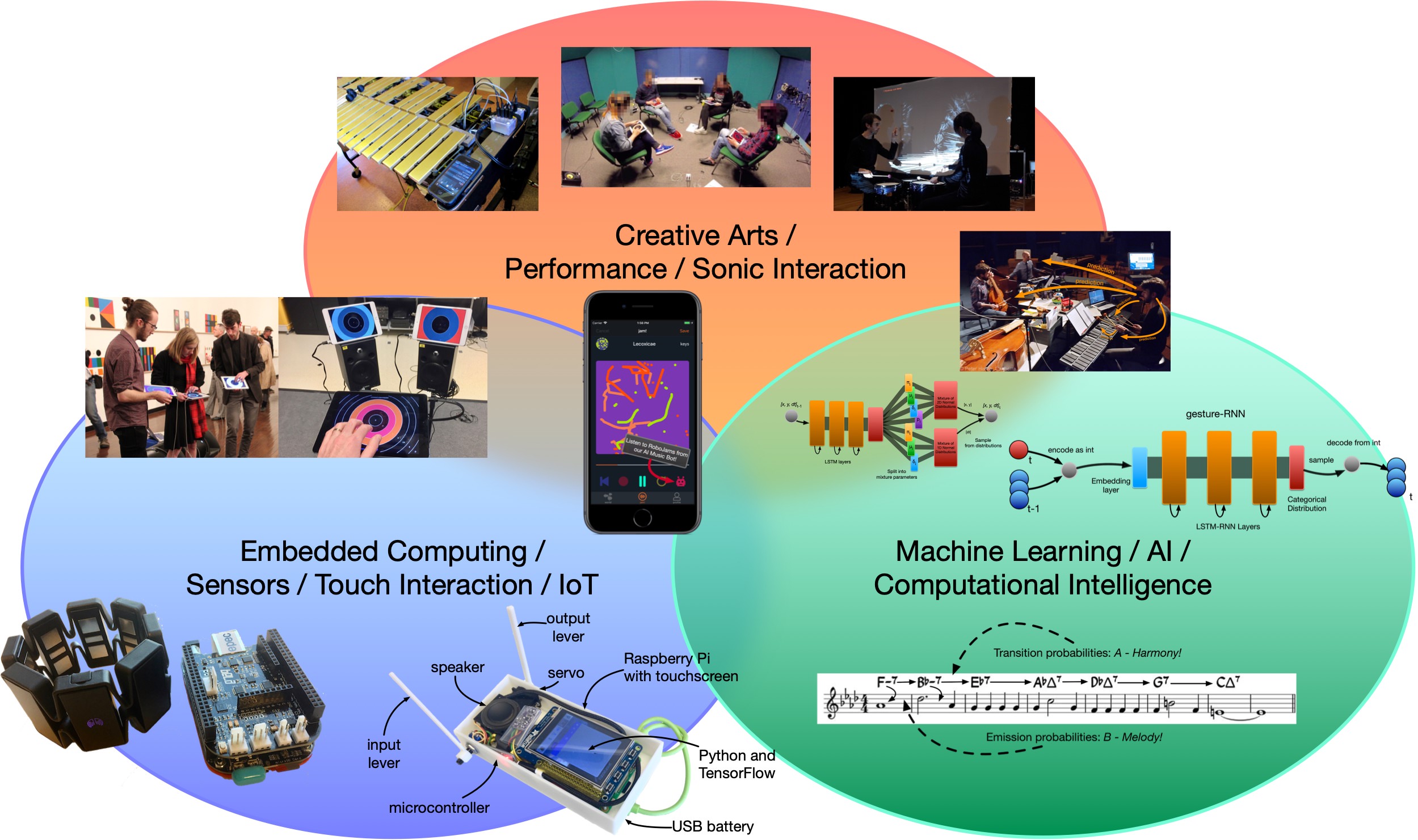
Prospective students should also have a look at my list of focus areas}.
Student Projects
I supervise student projects in sound and music computing, creativity support systems, computational creativity, music technology, and interactive systems. I’m interested in creating and studying new computing systems at the nexus of creative arts, physical embodiment, interaction, and intelligence.
My available projects are listed on the ANU School of Computing student project page.
Projects should align with my current focus areas}:
- spatial interaction (creating new musical instruments in VR/AR or with movement sensors)
- generative creative gestures with AI/ML
- guiding collaborative performances with AI models
- creating intelligent instruments in hardware
Experience with a creative field is a must. Computing students should have taken either COMP1720/6720 Art and Interaction Computing or COMP4350/8350 Sound and Music Computing and obtained excellent results.